Welcome to GongMH's Blog!
keep study.-
Linux基本命令--awk
1. 基本概念
awk是一种样式扫描与处理工具 awk是行处理器,相比较屏幕处理的优点,在处理庞大文件时不会出现内存溢出或是处理缓慢的问题,通常用来格式化文本信息。awk处理过程是依次对每一行进行处理,然后输出。
2. 基本应用
awk '{ sum += $1 }; END { print sum }' file awk -F: '{ print $1 }' /etc/passwd3. 工作流程
awk一次读取一行文本,按输入分隔符进行切片,切成多个组成部分,将每片直接保存在内建的变量中,$1,$2,$3,…。引用指定的变量,可以显示指定段,或者多个段。如果需要显示全部的,需要使用$0来引用。可以对单个片段进行判断,也可以对所有断进行循环判断。默认分隔符为空白字符。
4. 命令详解
4.1 用法
awk [ -F fs ] [ -v var=value ] [ 'prog' | -f progfile ] [ file ... ]-F指定分隔符,默认是空白字符-v定义变量-f指定脚本'prog'代码块file待处理的文件
4.2 代码块详解
代码块格式:
'BEGIN{} //{command1; command2} END{}'BEGIN初始化代码块,在对每一行进行处理之前,初始化代码,主要是引用全局变量,设置FS分隔符//匹配代码块,可以是字符串或正则表达式{}命令代码块,包含一条或多条命令;多条命令使用分号分隔END结尾代码块,在对每一行进行处理之后再执行的代码块,主要是进行最终计算或输出结尾摘要信息
4.3 内建变量
ARGC命令行参数个数ARGV命令行参数排列ENVIRON支持队列中系统环境变量的使用FILENAMEawk命令所处理的文件的名称FNR对每个文件进行行数单独编号FS设置输入域分隔符,等价于命令行 -F选项NF字段个数NR文件中的行数OFS输出域分隔符ORS输出记录分隔符RS控制记录分隔符$0表示整个当前行$1每行第一个字段- … …
$NF每行最后一个字段
5. 典型应用
(1)基本变量使用及输出
awk -F: '{print NR,NF$1,"\t",$0}' /etc/passwd //输出行号,每行字段数,每行第一个字段,整行的值 awk -F: 'NR==5 || NR==6{print}' /etc/passwd //输出第5行和第6行 awk -F: 'NR!=5 && NR!=6{print}' /etc/passwd //输出除了第5行和第6行(2)使用匹配代码块(字符匹配)
awk '/root/{print $0}' /etc/passwd //输出匹配root的行 awk '!/root/{print $0}' /etc/passwd //输出不匹配root的行 awk '/root|mail/{print}' /etc/passwd //输出匹配root或者mail的行(3)条件语句
awk -F: '$3>100 {print $0}' /etc/passwd awk -F: '{if($3>100){print $1}}' /etc/passwd awk -F: '$3+$4 > 200' /etc/passwd awk -F: '{if($3>100) print "large"; if($3>110) print "e large"}' /etc/passwd(4)输出结果重定向
awk 'NR!=1{print > "./filename"}' /etc/passwd awk 'NR!=1{print}' /etc/passwd > ./filename(5)格式化输出
awk -F: '{printf "%-8s %-10s %-10s\n",1,2,$3}' /etc/passwd(6)使用数组
netstat -anp|awk 'NR!=1{a[$6]++} END{for (i in a) print i,"\t",a[i]}'(7)其他
ls -l|awk 'BEGIN{sum=0} !/^d/{sum+=$5} END{print "total size is:",int(sum/1024),"KB"}' //统计当前目录下除了文件夹所有文件之和的大小 netstat -anp|awk '/LISTEN|CONNECTED/{sum[$6]++} END{for (i in sum) printf "%-10s %-6s %-3s \n", i," ",sum[i]}' //统计状态为LISTEN和CONNECT的连接数量
-
Redis源码分析(002)--基础数据结构
1. 概述
本文学习总结redis底层基础的数据结构,参考的redis版本为
3.2.9。2. sds
2.1 特点及应用
sds(简单动态字符串,simple dynamic string)是二进制安全的字符串,能够以O(1)的时间复杂度获取字符串的长度。并且能够避免缓存区溢出,操作前判断sds长度,不足则自动扩展。
2.2 数据结构
sds的数据结构就是普通的字符串,如下所示:
typedef char *sds;实际上,根据字符串长度的不同,redis定义了多个结构sds:
sdshdr5(未使用)、sdshdr8、sdshdr16、sdshdr32、sdshdr64,每种结构所对应的sds head不同。以sdshdr8为例,结构如下:struct __attribute__ ((__packed__)) sdshdr8 { uint8_t len; /* used */ uint8_t alloc; /* excluding the header and null terminator */ unsigned char flags; /* 3 lsb of type, 5 unused bits */ char buf[]; };注:结构体参数`__attribute__ ((__packed__))`说明结构体取消内存对齐优化,按照实际占用字节数进行对齐。len记录sds结构总字节数;alloc字符数组的长度(不包括头部和’\0’结束符);flags低3bit用来保存sds的类型,SDS_TYPE_5(0),SDS_TYPE_8(1),SDS_TYPE_16(2),SDS_TYPE_32(3),SDS_TYPE_64(4);buf记录实际字符串的值。
我们以
sdshdr8为例,如图介绍sds在内存中的结构:
另外实际上每个sds指针指向buf,因此sds也能像普通字符串一样处理。
sds能够根据字符串的长度自动改变类型。例如当字符串长度小于256时,type为
SDS_TYPE_8,当字符串长度大于255且小于65536时,会自动扩展到SDS_TYPE_16。具体判断如下函数所示:static inline char sdsReqType(size_t string_size) { if (string_size < 1<<5) return SDS_TYPE_5; if (string_size < 1<<8) //字符长度小于256 return SDS_TYPE_8; if (string_size < 1<<16) //字符长度小于65536 return SDS_TYPE_16; if (string_size < 1ll<<32) //字符长度小于4294967296 return SDS_TYPE_32; return SDS_TYPE_64; }2.3 知识点
#define SDS_HDR_VAR(T,s) struct sdshdr##T *sh = (void*)((s)-(sizeof(struct sdshdr##T))); //注意无分号 #define SDS_HDR(T,s) ((struct sdshdr##T *)((s)-(sizeof(struct sdshdr##T))))在c语言中,define中的'##'表示连接的意思。例如SDS_HDR_VAR(8,s)SDS_HDR_VAR(T,s)表示根据s,定义指针sh,并初始化指向实际sds的起始地址,用法:SDS_HDR_VAR(16,s);SDS_HDR(T,s)表示一个指向实际sds的起始地址的指针,用法:SDS_HDR(32,s)->len;2.4 重要api
仅列出重要的api函数,部分省略。
//根据长度创建相应类型的sds,并初始化sds(若init不为空) sds sdsnewlen(const void *init, size_t initlen); //释放一个sds void sdsfree(sds s); //s后拼接长度为len的t字符串 sds sdscatlen(sds s, const void *t, size_t len); //从t中复制长度为len的二进制安全的字符串到s中 sds sdscpylen(sds s, const char *t, size_t len); //使用类似printf的格式在s后拼接字符串,基于sprintf() family functions,较慢 sds sdscatvprintf(sds s, const char *fmt, va_list ap); //使用类似printf的格式在s后拼接字符串,自己实现,较快。但是实现的格式是printf-alike的子集 sds sdscatfmt(sds s, char const *fmt, ...); //移除s两端在cset中的字符 sds sdstrim(sds s, const char *cset); //获取s的子集 void sdsrange(sds s, int start, int end); //比较两个sds int sdscmp(const sds s1, const sds s2); //将s根据sep进行切割,返回一个sds数组,count为数组元素个数 sds *sdssplitlen(const char *s, int len, const char *sep, int seplen, int *count); //为s拼接字符,非打印字符会被转换为"\x<hex-number>" sds sdscatrepr(sds s, const char *p, size_t len); //将line转换为参数sds数组,argc为数组中元素个数 sds *sdssplitargs(const char *line, int *argc); //将s中from的元素替换成对应的to元素 sds sdsmapchars(sds s, const char *from, const char *to, size_t setlen); //将argv中的每个元素(除了最后一个)连接上sep,连接成一个sds sds sdsjoin(char **argv, int argc, char *sep); /* Low level functions exposed to the user API */ //增加s的空闲区域,可以让随后的操作在s后增加addlen字节。 //注意,该函数不会改变s的len。 sds sdsMakeRoomFor(sds s, size_t addlen); //增加/减少sds的长度 void sdsIncrLen(sds s, int incr); //重新分配sds,以便去除多余的字节 sds sdsRemoveFreeSpace(sds s); //返回s占用总的字节数,即sds头长度+字符串长度+空余长度+结束(sdsHeader + string + free + 1) size_t sdsAllocSize(sds s); //根据s获取sds的真实起始地址 void *sdsAllocPtr(sds s);
-
UNIX socket通信
1. 引言
套接字(socket)主要用于实现进程间通讯,在计算机网络通讯方面被广泛使用。套接字既能满足单台计算机进程间的通信也能满足不同计算机间的通信。本文仅限于讨论TCP/IP协议栈的通信标准。
2. 套接字描述符
套接字是通信端点的抽象。与应用程序要使用文件描述符访问文件一样,访问套接字也需要用套接字描述符。套接字描述符在UNIX系统是用文件描述符实现的。事实上,许多处理文件描述符的函数(如read和write)都可以处理套接字描述符。
要创建一个套接字,可以使用sockrt函数。该函数成功则返回文件(套接字)描述符,失败则返回-1.
#include <sys/socket.h> int socket(int domain, int type, int protocol);(1)参数
domain(域)确定通信的特性,包括地址格式。域 描述 AF_INET IPv4因特网域 AF_INET6 IPv6因特网域 AF_UNIX UNIX域 AF_UNSPEC 未指定 (2)参数
type确定套接字的类型,进一步确定通信的特征。类型 描述 SOCK_DGRAM 长度固定,无连接的不可靠报文传递 SOCK_RAW IP协议的数据报接口 SOCK_SEQPACKET 长度固定,有序、可靠的面向连接报文传递 SOCK_STREAM 有序、可靠、双向的面向连接字节流 (3)参数
protocol通常是0,表示按给定的域和套接字类型选择默认协议。当对同一域和套接字类型支持多个协议时,可以使用protocol指定一个特定的协议。在AF_INET通信域中套接字类型SOCK_STREAM的默认协议是TCP(传输控制协议)。在SOCK_DGRAM通信域中套接字类型SOCK_DGRAM的默认协议是UDP(用户数据报协议)。 对于数据报(SOCK_DGRAM)接口,与对方通信时是不需要逻辑链接的。只需要送出一个报文,其地址是一个对方进程所使用的套接字。因此数据报提供的是无连接的服务。数据报是一种自包含报文。每个发送的报文都是独立、无序,并且可能会有丢包,每个报文可能会发送给不通的接收方。 字节流(SOCK_STREAM)要求在交换数据之前,在本地套接字和与之通信的远程套接字之间建立一个逻辑连接。每个连接都是端到端的通信信道。会话中不包含地址信息。SOCK_STREAM提供的是字节流服务,当从套接字读取数据时,需要经过若干次函数调用才能获取发送来的所有数据。调用socket与调用open类似,均可获得用于输入/输出的文件描述符。当不再需要该文件描述符时,调用close来关闭对文件或套接字的访问,并且释放该文件描述符以便重新使用。
虽然套接字描述符本质上是一个文件描述符,但不是所有参数为文件描述符的函数都可以接受套接字描述符。例如,由于套接字不支持文件偏移量lseek不能处理套接字描述符。
套接字通信是双向的,可以通过函数
shutdown来禁止套接字的输入/输出。该函数成功返回0,失败则返回-1。#include <sys/socket.h> int shutdown(int sockfd, int how);如果how是SHUT_RD(关闭读端),则无法从套接字独处数据;如果how是SHUT_WR(关闭写端),则无法使用套接字发送数据;如果how是SHUT_RDWR,则同事无法读取和发送数据。既然close可以关闭套接字,为什么还要使用shutdown?首先,close只有在最后一个活动引用被关闭时才释放网络端点,而shutdown允许使用套接字处于不活动的状态;其次,关闭套接字双向传输中的一个方向会给通信带来许多便利。
3. 将套接字与地址绑定
对于服务器来说,需要给一个接收客户端请求的套接字绑定一个众所周知的地址。客户端则需要在
/etc/services或某个名字服务(name service)中注册服务器地址。在服务端,可以用bind函数将地址绑定到一个套接字。该函数成功返回0,失败则返回-1。
#include <sys/socket.h> int bind(int sockfd, const struct sockaddr *addr, socketlen_t len);对于所使用的地址有一些限制:
在进程运行的机器上,指定的地址必须有效,不能指定一个其他机器的地址; 地址必须和创建套接字时的地址族所支持的格式相匹配; 端口号必须不小于1024,除非改进成具有响应的权限(超级用户); 一般只有套接字端点能够与地址绑定(尽管有些协议徐允许多重绑定)。对于因特网域,如果指定IP地址为INADDR_ANY,套接字端点可以被绑定到都有的系统网络接口,即可以接收到系统所有网卡的数据包。
可以调用函数getsockname来获取绑定到一个套接字的地址。成功返回0,失败则返回-1。
#include <sys/socket.h> int getsockname(int sockfd, struct sockaddr *restrict addr, socklen_t *restrict alenp);调用getsockname之前,设置alenp为一个指向整数的指针,该整数指定缓冲区sockaddr的大小。返回时,该整数会被设置成返回地址的大小。如果当前没有绑定到该套接字的地址,其结果没有定义。
如果套接字已经和对方连接,调用getpeername来获取对方地址。该函数成功返回0,失败则返回-1。
#include <sys/socket.h> int getpeername(int sockfd, struct sockaddr * restrict addr, socklen_t *erstrict alenp);除了返回对方的地址之外,函数getpeername和getsockname一样。
4. 建立连接
如果是面向连接的网络服务(SOCK_STREAM或SOCK_SEQPACKET),在开始交换数据之前,需要在请求服务的进程套接字(客户端)和提供服务的进程套接字(服务器)之间建立一个连接。可以使用connect建立连接。该函数成功返回0,失败则返回-1。
#include <sys/socket.h> int connect(int sockfd, const struct sockaddr *addr, socklen_t len);在connect中所指定的地址是将要通信的服务器地址。如果sockfd没有绑定到一个地址,connect会给调用者绑定一个默认地址。
函数connect还可以用于无连接的网络服务(SOCK_DGRAM)。如果在SOCK_DGRAM套接字上调用connect,所有发送报文的目标地址设为connect调用中指定的地址,这样每次传送报文时就不用再提供地址。但是只能接收来自指定地址的报文。
服务器调用listen来宣告可以接受连接请求。该函数成功返回0,失败则返回-1。
#include <sys/socket.h> int listen(int sockfd, int backlog);参数backlog提供了一个提示,用于表示改进成所要入队的连接请求数量。其实际值由系统决定,上限在
<sys/socket.h>中的SOMAXCONN指定(对于TCP,其默认值为128)。一旦队列满,系统会拒绝多余的连接请求,所以backlog的值应该基于服务器期望负载和接受连接数与启动服务的处理能力来选择。
一旦服务器调用了listen,套接字就能接收连接请求。使用accept函数来获得连接请求并建立连接。该函数成功返回文件(套接字)描述符,失败则返回-1。
#include <sys/socket.h> int accept(int sockfd, struct sockaddr *restrict addr, socklen_t *restrict len);函数accept返回的文件描述符是套接字描述符,该描述符连接到调用connect的客户端。这个新的套接字描述符和原始套接字(sockfd)具有相同的套接字类型和地址族。传给accept的原始套接字没有关联到这个连接,而是继续保持可用状态并接受其他连接请求。
如果不关心客户端标识,可以将参数addr和len设置为NULL。否则,在调用accept之前,应将参数addr设置为足够大的缓冲区来存放地址,len设置为该缓冲区大小的证书的指针。
如果没有连接请求等待处理,accept会阻塞直到一个请求到来。如果sockfd处于非阻塞模式,accept会返回-1并将errno设置为EAGAIN或EWOULDBLOCK。
5. 数据传输
只要建立连接,就可以使用read和write来通过套接字通信。尽管可以使用read和write交换数据,但是socket提供了六个套接字函数来进行通信。
最简单的是send函数,可以指定标志来改变出来传输数据的方式。该函数成功返回发送的字节数,失败返回-1。
#include <sys/socket.h> ssize_t send(int sockfd, const void *buf, size_t nbytes, int flags);使用send时套接字必须已经连接。参数flags标志如下:
标志 描述 MSG_DONTROUTE 勿将数据路由出本地网络 MSG_DONTWAIT 允许非阻塞操作 MSG_EOR 如果协议支持,此为记录结束 MSG_OOB 如果协议支持,发送带外数据 如果send成功返回,斌不能表示连接另一端的进程接收到数据。只能保证send成功返回时,数据已经无错误地发送到网络上。
对于支持为报文设限的协议,如果单个报文超过协议所支持的最大尺寸,send失败并将errno设置为EMSCSIZE;对于字节流协议,send会阻塞知道整个数据被传输。
函数sendto和send很类似,区别在于sendto允许在无连接的套接字上指定一个目标地址。该函数成功返回发送的字节数,失败返回-1。
#include <sys/socket.h> ssize_t sendto(int sockfd, const void *buf, size_t nbytes, int flags, const struct sockaddr *destaddr, socklen_t destlen);面向连接的套接字,目标地址是可以忽略的,因为目标地址蕴含在连接中。对于无连接的套接字,不能使用send,除非在调用connect时预先设定了目标地址,或者采用sendto来提供。
可以调用带有msghdr结构的sendmsg来指定多重缓冲区传输数据。该函数成功返回发送的字节数,失败返回-1。
#include <sys/socket.h> ssize_t sendmsg(int sockfd, const struct msghdr *msg, size_t nbytes, int flags);接收数据可以使用recv函数。成功返回以字节计数的消息长度,若无可用消息或者对方已经按序结束则返回0,失败则返回-1。
#include <sys/socket.h> ssize_t recv(int sockfd, void * buf, size_t nbytes, int flags);调用标识参数flags标志如下:
标志 描述 MSG_OOB 如果协议支持,发送带外数据 MSG_PEEK 返回报文内容而不真正取走报文 MSG_TRUNC 即使报文被截断,要求返回的是报文的实际长度 MSG_WAITALL 等待直到所有的数据可用(仅SOCK_STREAM) 当指定MSG_PEEK标志时,可以查看下一个要读的数据但不会真正取走。当再次调用read或者recv函数时会返回刚才查看的数据。 对于SOCK_DGRAM和SOCK_SEQPACKET套接字,标志MSG_WAITALL无影响,因为这些基于报文的套接字类型,一次读取就返回整个报文;对于SOCK_STREAM套接字,MSG_WAITALL会等所需数据全部收到,recv函数才会返回。如果发送者已经调用shutdown来结束传输,或者网络协议支持默认的顺序关系并且发送端已经关闭,那么当所有的数据接收完毕后,recv返回0。
接收数据,recvfrom函数可以获取数据发送者的源地址。成功返回以字节计数的消息长度,若无可用消息或者对方已经按序结束则返回0,失败则返回-1。
#include <sys/socket.h> ssize_t recvfrom(int sockfd, void *restrict buf, size_t len, int flags, struct sockaddr *restrict addr, socklen_t * restrict addrlen);如果addr非空,则其包含数据发送者的套接字端点地址。recvfrom通常用于无连接的套接字。
为了将接收到的数据送入多个缓冲区,或者希望接收辅助数据,可以使用recvmsg。
#include <sys/socket.h> ssize_t recvmsg(int sockfd, struct msghdr *msg, int flags);结构msghdr被recvmsg用于指定接收数据的输入缓冲区。
6. 套接字选项
套接字机制提供两个套接字选项接口来控制套接字行为。可以获取或设置三种选项
通用选项,工作在所用的套接字类型上; 在套接字层次管理的选项,但是依赖下层协议的支持; 特定与某协议的选项,为每个协议所独有。setsockopt用来设置选项,成功返回0,失败则返回-1。
#include <sys/socket.h> int setsockopt(int sockfd, int level, int option, const void *val, socklen_t len);getsockopt用来设置选项,成功返回0,失败则返回-1。
#include <sys/socket.h> int getsockopt(int sockfd, int level, int option, void *restrict val, socklen_t *restirct lenp);7. 带外数据
带外数据(Out-of-band data)是一些通信协议所支持的可选特征,允许更高优先级的数据比普通数据有限传输。即使传输队列已经有数据,带外数据先行传输。TCP支持带外数据,但是UDP不支持。
8. 非阻塞和异步I/O
通常,recv函数没有数据可用时会阻塞等待。同样,当套接字输出队列没有足够的空间来发送消息时函数send会阻塞。在套接字非阻塞模式下,行为会改变。在这些情况下,这些函数不会阻塞而是返回失败,设置errno为EWOULDBLOCK或者EAGAIN。当这些发生时,可以使用poll或select来判断何时能接收或者传输数据。
在基于套接字的异步I/O中,当能够从套接字中读取数据或者套接字写队列中的空间变得可用时,可以安排发送信号SIGIO。通过两个步骤来使用异步I/O:
(1)建立套接字拥有者关系,信号可以被传送到合适的进程,有三种方式: a.在fcntl使用F_SETOWN命令; b.在ioctl中使用FIOSETOWN命令; c.在ioctl中使用SIOCSPGRP命令。 (2)通知套接字当I/O操作不会阻塞时发信号告知,有两种方式: a.在fcntl中使用F_SETFL命令并启动文件标志O_ASYNC; b.在ioctl中使用FIOASYNC。9. 总结
如何选择合适的套接字类型?何时采用面相俩节的套接字,何时采用无连接的套接字呢?答案取决于要做的服务以及对错误的容忍程度。
包的最大尺寸是通信协议的特性。对于无连接的套接字,数据包到来可能已经没有次序,因此当所有的数据不能放在一个包里的时候,在应用程序中必须关心包的次序。对于无连接的套接字,包可能丢失。如果应用程序不能容忍这种丢失,则必须使用面向连接的套接字。
容忍丢包意味着两种选择。一种是对包进行编号,如果发现丢包则要求对方重新传输,并且识别重复包。另一种是让用户重试来处理错误。
面向连接的套接字的缺点在于需要更多的时间和工作来建立一个连接,并且每个连接需要从操作系统中消耗更多资源。
如下分别是TCP 和 UDP socket通信的流程图示。
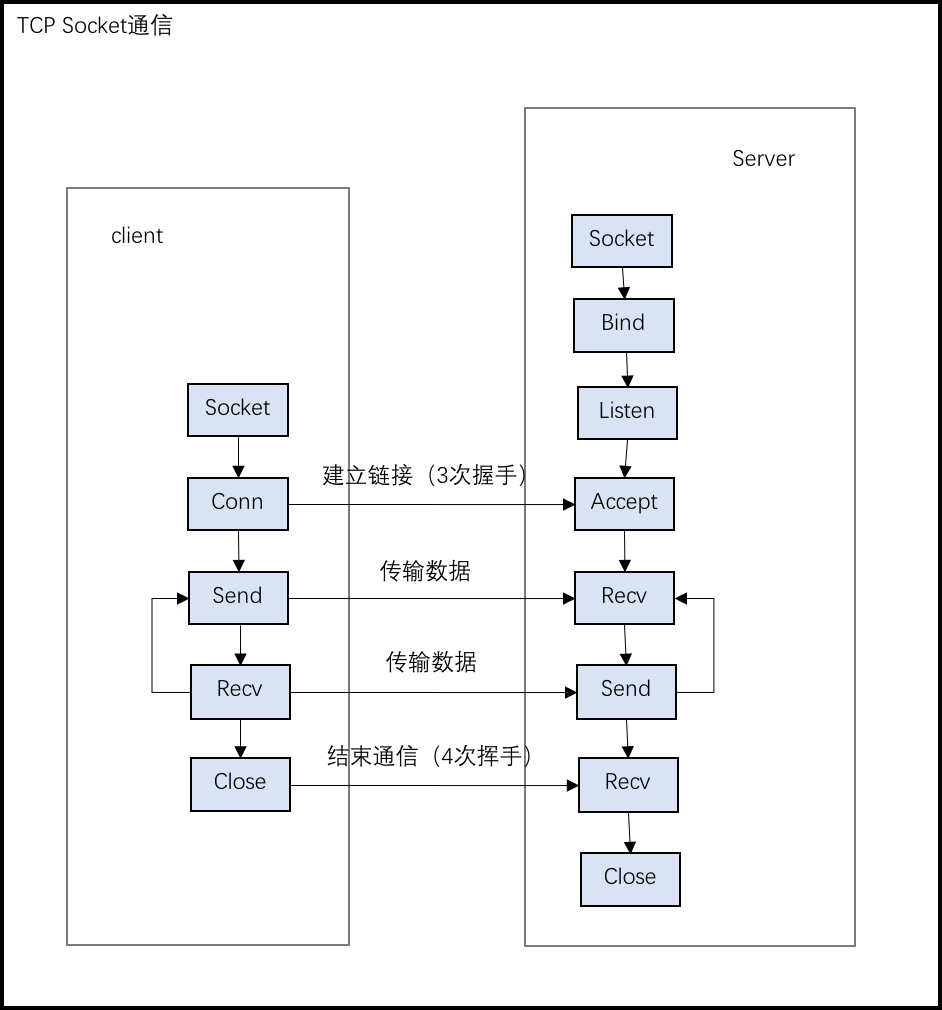
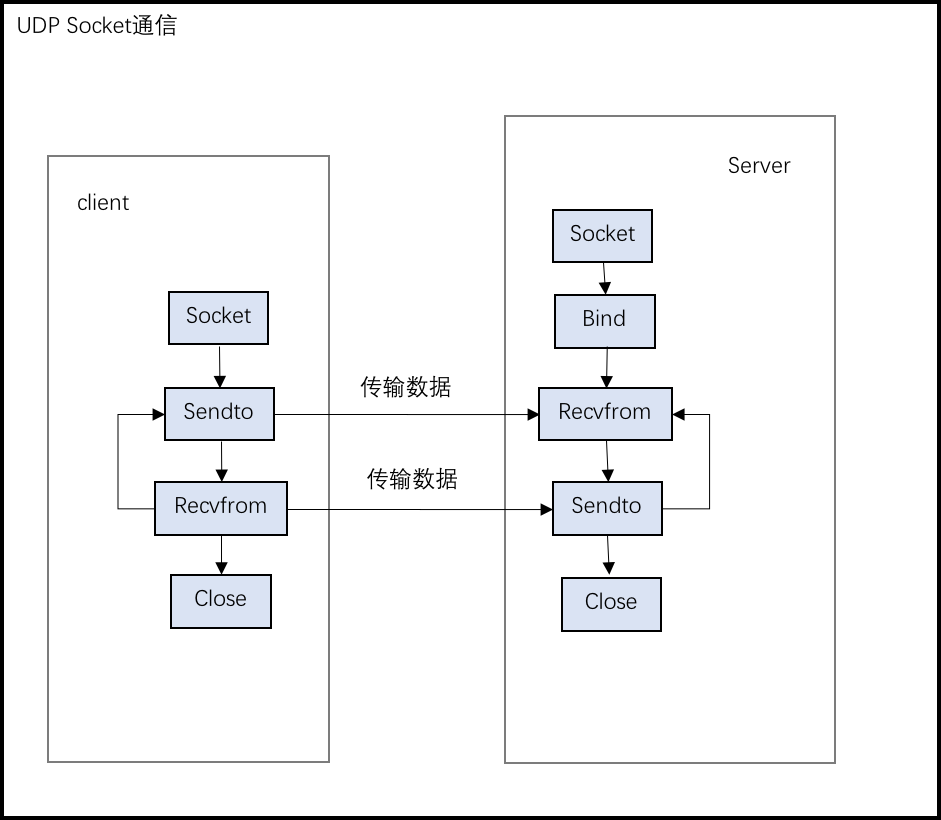
-
面试算法基础题
1.数组
面试题1.1:数组中出现次数超过一半的数字
解法1:快排模式,找中位数
解法2:该数字个数大于其他数字个数之和
面试题1.2:数组中唯一重复的数字
解法1:数组下边(条件 n个数, 0<= a[i] <= n)
解法2:bitmap
面试题1.3:数组中最小的K个数
解法1:快排模式,找index = k
解法2:取出最小k个(海量数据)
面试题1.4:连续子数组最大和
面试题1.5:数组中的逆序对
面试题1.6:数字k在排序数组中出现的次数
解法1:分别二分查找k第一次出现的位置和k最后一次出现的位置
面试题1.7:数组中除了2个数字出现1次,其他数字都出现2次
解法1:将所有元素异或,取出结果中的一个1的index,然后将数组分成2组,分别求出异或结果。
2.字符串
3.链表
面试题3.1:两个链表的第一个公共节点
解法1:分别把两个链表的节点放到两个栈中,接下来出栈比较最后一个相同节点
解法2:计算两个链表长度,较长的链表先走长度之差步,然后继续比较第一个相同节点
-
Redis源码分析(001)--util.c
1 函数stringmatchlen
规则说明和分析
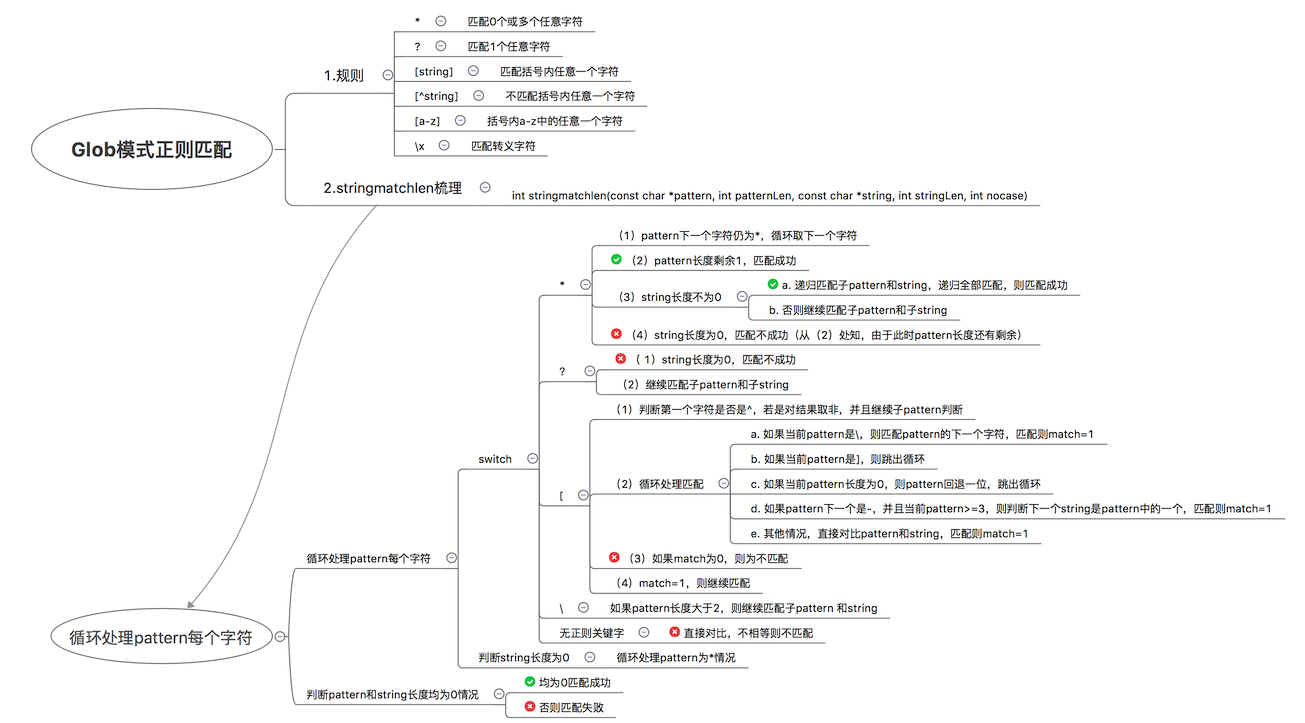
/* Glob-style pattern matching. */ int stringmatchlen(const char *pattern, int patternLen, const char *string, int stringLen, int nocase) { while(patternLen) { //对于pattern第一个字符 switch(pattern[0]) { //1. 如果是*,匹配任意 case '*': //1.1 下一个字符仍是*,继续查找下一个pattern字符 while (pattern[1] == '*') { pattern++; patternLen--; } //1.2 pattern字符串长度为1,则为匹配 if (patternLen == 1) return 1; /* match */ //1.3 stringLen不为零 while(stringLen) { //1.3.1 递归匹配子pattern 和 string,如果全部匹配,则为匹配 if (stringmatchlen(pattern+1, patternLen-1, string, stringLen, nocase)) return 1; /* match */ //1.3.2 去除string首字符,继续匹配子string string++; stringLen--; } //1.4 string到尾部还没匹配,则为不匹配 return 0; /* no match */ break; // 2. 如果是?,分为2中情况 case '?': //2.1 string长度为0,则为不匹配 if (stringLen == 0) return 0; /* no match */ //2.2 去除string首字符,继续匹配子string string++; stringLen--; break; //3. 如果是[,分为 case '[': { int not, match; pattern++; patternLen--; //3.1 pattern的下一字符如果是^,往下取一位 not = pattern[0] == '^'; if (not) { pattern++; patternLen--; } match = 0; //3.2 循环处理 while(1) { //3.2.1 如果pattern下一字符是\,则匹配下一字符 if (pattern[0] == '\\') { pattern++; patternLen--; if (pattern[0] == string[0]) match = 1; //3.2.2 如果pattern下义字符是],则跳出循环,继续匹配 } else if (pattern[0] == ']') { break; //3.2.3 如果pattern长度为0,pattern回退一位,跳出循环,继续匹配 } else if (patternLen == 0) { pattern--; patternLen++; break; //3.2.4 如果pattern下一位是-,并且长度大于等于3 } else if (pattern[1] == '-' && patternLen >= 3) { int start = pattern[0]; int end = pattern[2]; int c = string[0]; if (start > end) { int t = start; start = end; end = t; } if (nocase) { start = tolower(start); end = tolower(end); c = tolower(c); } pattern += 2; patternLen -= 2; if (c >= start && c <= end) match = 1; //3.2.5 其他情况,直接比对pattern和string } else { if (!nocase) { if (pattern[0] == string[0]) match = 1; } else { if (tolower((int)pattern[0]) == tolower((int)string[0])) match = 1; } } pattern++; patternLen--; } if (not) match = !match; //3.3 match为0,则为不匹配 if (!match) return 0; /* no match */ string++; stringLen--; break; } //4. 如果是\,继续执行default case '\\': //4.1 如果pattern长度大于等于2,去除这个字符继续匹配 if (patternLen >= 2) { pattern++; patternLen--; } /* fall through */ //5. 其他情况无正则关键字,直接比对字符,若不相等则为不匹配,否则继续 default: if (!nocase) { if (pattern[0] != string[0]) return 0; /* no match */ } else { if (tolower((int)pattern[0]) != tolower((int)string[0])) return 0; /* no match */ } string++; stringLen--; break; } pattern++; patternLen--; //6. 如果string长度为0, 循环判断pattern if (stringLen == 0) { while(*pattern == '*') { pattern++; patternLen--; } break; } } //7. 全部匹配完成 if (patternLen == 0 && stringLen == 0) return 1; return 0; }
-
linux下字符串和文件的md5值计算
1、计算指定文件的MD5值
md5sum a.rmvb //输出结果类似如下: 8dab209d0b7c7fb1afb071f0855a8c37 a.rmvb即计算出的md5值加上文件名
2、计算字符串MD5值
echo -n “password” | md5sum //输出: 5f4dcc3b5aa765d61d8327deb882cf99 -上面
echo加-n的作用是不输出回车符,因为echo命令默认会添加一回车符。 像如果是:echo “password” | md5sum //那输出的将会是: 286755fad04869ca523320acce0dc6a4 -因此在命令行下,计算字符串的MD5值一般是要加-n参数。